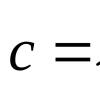В том случае, если полученное значение критерия χ 2 больше критического, делаем вывод о наличии статистической взаимосвязи между изучаемым фактором риска и исходом при соответствующем уровне значимости.
Пример расчета критерия хи-квадрат Пирсона
Определим статистическую значимость влияния фактора курения на частоту случаев артериальной гипертонии по рассмотренной выше таблице:
1. Рассчитываем ожидаемые значения для каждой ячейки:
2. Находим значение критерия хи-квадрат Пирсона:
χ 2 = (40-33.6) 2 /33.6 + (30-36.4) 2 /36.4 + (32-38.4) 2 /38.4 + (48-41.6) 2 /41.6 = 4.396.
3. Число степеней свободы f = (2-1)*(2-1) = 1. Находим по таблице критическое значение критерия хи-квадрат Пирсона, которое при уровне значимости p=0.05 и числе степеней свободы 1 составляет 3.841.
4. Сравниваем полученное значение критерия хи-квадрат с критическим: 4.396 > 3.841, следовательно зависимость частоты случаев артериальной гипертонии от наличия курения - статистически значима. Уровень значимости данной взаимосвязи соответствует p<0.05.
Также критерий хи-квадрат Пирсона вычисляется по формуле
Но для таблицы 2х2 более точные результаты дает критерий с поправкой Йетса

Если  то Н(0)
принимается,
то Н(0)
принимается,
В случае ![]() принимается Н(1)
принимается Н(1)
Когда число наблюдений невелико и в клетках таблицы встречается частота меньше 5, критерий хи-квадрат неприменим и для проверки гипотез используется точный критерий Фишера . Процедура вычисления этого критерия достаточно трудоемка и в этом случае лучше воспользоваться компьютерными программами статанализа.
По таблице сопряженности можно вычислить меру связи между двумя качественными признаками – ею является коэффициент ассоциации Юла Q (аналог коэффициента корреляции)

Q лежит в пределах от 0 до 1. Близкий к единице коэффициент свидетельствует о сильной связи между признаками. При равенстве его нулю – связь отсутствует.
Аналогично используется коэффициент фи-квадрат (φ 2)
ЗАДАЧА-ЭТАЛОН
В таблице описывается связь между частотой мутации у групп дрозофил с подкормкой и без подкормки
Анализ таблицы сопряженности
Для анализа таблицы сопряженности выдвигается Н 0 - гипотеза.т.е.отсуствие влияния изучаемого признака на результат исследования.Для этого рассчитывается ожидаемая частота,и строится таблица ожидания.
Таблица ожидания
| группы | Чило культур | Всего | ||||
| Давшие мутации | Не давшие мутации | |||||
| Фактическая частота | Ожидаемая частота | Фактическая частота | Ожидаемая частота | |||
| С подкормкой | ||||||
| Без подкормкой | ||||||
| всего | ||||||
Метод №1
Определяем частоту ожидания:
2756 – Х ![]() ;
;
2. 3561 – 3124
Если число наблюдении в группах мало, при применении Х 2, в случае сопоставления фактических и ожидаемых частот при дискретных распределениях сопряжено с некоторой неточностью.Для уменьшения неточности применяют поправку Йейтса.
В этой статье речь будет идти о исследовании зависимости между признаками, или как больше нравится - случайными величинами, переменными. В частности, мы разберем как ввести меру зависимости между признаками, используя критерий Хи-квадрат и сравним её с коэффициентом корреляции.
Для чего это может понадобиться? К примеру, для того, чтобы понять какие признаки сильнее зависимы от целевой переменной при построении кредитного скоринга - определении вероятности дефолта клиента. Или, как в моем случае, понять какие показатели нобходимо использовать для программирования торгового робота.
Отдельно отмечу, что для анализа данных я использую язык c#. Возможно это все уже реализовано на R или Python, но использование c# для меня позволяет детально разобраться в теме, более того это мой любимый язык программирования.
Начнем с совсем простого примера, создадим в экселе четыре колонки, используя генератор случайных чисел:
X
=СЛУЧМЕЖДУ(-100;100)
Y
=X
*10+20
Z
=X
*X
T
=СЛУЧМЕЖДУ(-100;100)
Как видно, переменная Y линейно зависима от X ; переменная Z квадратично зависима от X ; переменные X и Т независимы. Такой выбор я сделал специально, потому что нашу меру зависимости мы будем сравнивать с коэффициентом корреляции . Как известно, между двумя случайными величинами он равен по модулю 1 если между ними самый «жесткий» вид зависимости - линейный. Между двумя независимыми случайными величинами корреляция нулевая, но из равенства коэффициента корреляции нулю не следует независимость . Далее мы это увидим на примере переменных X и Z .
Сохраняем файл как data.csv и начинаем первые прикиди. Для начала рассчитаем коэффициент корреляции между величинами. Код в статью я вставлять не стал, он есть на моем github . Получаем корреляцию по всевозможным парам:

Видно, что у линейно зависимых X и Y коэффициент корреляции равен 1. А вот у X и Z он равен 0.01, хотя зависимость мы задали явную Z =X *X . Ясно, что нам нужна мера, которая «чувствует» зависимость лучше. Но прежде, чем переходить к критерию Хи-квадрат, давайте рассмотрим что такое матрица сопряженности.
Чтобы построить матрицу сопряженности мы разобьём диапазон значений переменных на интервалы (или категорируем). Есть много способов такого разбиения, при этом какого-то универсального не существует. Некоторые из них разбивают на интервалы так, чтобы в них попадало одинаковое количество переменных, другие разбивают на равные по длине интервалы. Мне лично по духу комбинировать эти подходы. Я решил воспользоваться таким способом: из переменной я вычитаю оценку мат. ожидания, потом полученное делю на оценку стандартного отклонения. Иными словами я центрирую и нормирую случайную величину. Полученное значение умножается на коэффициент (в этом примере он равен 1), после чего все округляется до целого. На выходе получается переменная типа int, являющаяся идентификатором класса.
Итак, возьмем наши признаки X и Z , категорируем описанным выше способом, после чего посчитаем количество и вероятности появления каждого класса и вероятности появления пар признаков:

Это матрица по количеству. Здесь в строках - количества появлений классов переменной X , в столбцах - количества появлений классов переменной Z , в клетках - количества появлений пар классов одновременно. К примеру, класс 0 встретился 865 раз для переменной X , 823 раза для переменной Z и ни разу не было пары (0,0). Перейдем к вероятностям, поделив все значения на 3000 (общее число наблюдений):

Получили матрицу сопряженности, полученную после категорирования признаков. Теперь пора задуматься над критерием. По определению, случайные величины независимы, если независимы сигма-алгебры , порожденные этими случайными величинами. Независимость сигма-алгебр подразумевает попарную независимость событий из них. Два события называются независимыми, если вероятность их совместного появления равна произведению вероятностей этих событий: Pij = Pi*Pj . Именно этой формулой мы будем пользоваться для построения критерия.
Нулевая гипотеза : категорированные признаки X и Z независимы. Эквивалентная ей: распределение матрицы сопряженности задается исключительно вероятностями появления классов переменных (вероятности строк и столбцов). Или так: ячейки матрицы находятся произведением соответствующих вероятностей строк и столбцов. Эту формулировку нулевой гипотезы мы будем использовать для построения решающего правила: существенное расхождение между Pij и Pi*Pj будет являться основанием для отклонения нулевой гипотезы.
Пусть - вероятность появления класса 0 у переменной X
. Всего у нас n
классов у X
и m
классов у Z
. Получается, чтобы задать распределение матрицы нам нужно знать эти n
и m
вероятностей. Но на самом деле если мы знаем n-1
вероятность для X
, то последняя находится вычитанием из 1 суммы других. Таким образом для нахождения распределения матрицы сопряженности нам надо знать l=(n-1)+(m-1)
значений. Или мы имеем l
-мерное параметрическое пространство, вектор из которого задает нам наше искомое распределение. Статистика Хи-квадрат будет иметь следующий вид:
и, согласно теореме Фишера, иметь распределение Хи-квадрат с n*m-l-1=(n-1)(m-1)
степенями свободы.
Зададимся уровнем значимости 0.95 (или вероятность ошибки первого рода равна 0.05). Найдем квантиль распределения Хи квадрат для данного уровня значимости и степеней свободы из примера (n-1)(m-1)=4*3=12 : 21.02606982. Сама статистика Хи-квадрат для переменных X и Z равна 4088.006631. Видно, что гипотеза о независимости не принимается. Удобно рассматривать отношение статистики Хи-квадрат к пороговому значению - в данном случае оно равно Chi2Coeff=194.4256186 . Если это отношение меньше 1, то гипотеза о независимости принимается, если больше, то нет. Найдем это отношение для всех пар признаков:

Здесь Factor1
и Factor2
- имена признаков
src_cnt1
и src_cnt2
- количество уникальных значений исходных признаков
mod_cnt1
и mod_cnt2
- количество уникальных значений признаков после категорирования
chi2
- статистика Хи-квадрат
chi2max
- пороговое значение статистики Хи-квадрат для уровня значимости 0.95
chi2Coeff
- отношение статистики Хи-квадрат к пороговому значению
corr
- коэффициент корреляции
Видно, что независимы (chi2coeff<1) получились следующие пары признаков - (X,T ), (Y,T ) и (Z,T ), что логично, так как переменная T генерируется случайно. Переменные X и Z зависимы, но менее, чем линейно зависимые X и Y , что тоже логично.
Код утилиты, рассчитывающей данные показатели я выложил на github, там же файл data.csv. Утилита принимает на вход csv-файл и высчитывает зависимости между всеми парами колонок: PtProject.Dependency.exe data.csv
В практике биологических исследований часто бывает необходимо проверить ту или иную гипотезу, т. е. выяснить, насколько полученный экспериментатором фактический материал подтверждает теоретическое предположение, насколько анализируемые данные совпадают с теоретически ожидаемыми. Возникает задача статистической оценки разницы между фактическими данными и теоретическим ожиданием, установления того, в каких случаях и с какой степенью вероятности можно считать эту разницу достоверной и, наоборот, когда ее следует считать несущественной, незначимой, находящейся в пределах случайности. В последнем случае сохраняется гипотеза, на основе которой рассчитаны теоретически ожидаемые данные или показатели. Таким вариационно-статистическим приемом проверки гипотезы служит метод хи-квадрат (χ 2). Этот показатель часто называют «критерием соответствия» или «критерием согласия» Пирсона. С его помощью можно с той или иной вероятностью судить о степени соответствия эмпирически полученных данных теоретически ожидаемым.
С формальных позиций сравниваются два вариационных ряда, две совокупности: одна – эмпирическое распределение, другая представляет собой выборку с теми же параметрами (n , M , S и др.), что и эмпирическая, но ее частотное распределение построено в точном соответствии с выбранным теоретическим законом (нормальным, Пуассона, биномиальным и др.), которому предположительно подчиняется поведение изучаемой случайной величины.
В общем виде формула критерия соответствия может быть записана следующим образом:
где a – фактическая частота наблюдений,
A – теоретически ожидаемая частота для данного класса.
Нулевая гипотеза предполагает, что достоверных различий между сравниваемыми распределениями нет. Для оценки существенности этих различий следует обратиться к специальной таблице критических значений хи-квадрат (табл. 9П ) и, сравнив вычисленную величину χ 2 с табличной, решить, достоверно или не достоверно отклоняется эмпирическое распределение от теоретического. Тем самым гипотеза об отсутствии этих различий будет либо опровергнута, либо оставлена в силе. Если вычисленная величина χ 2 равна или превышает табличную χ ² (α , df ) , решают, что эмпирическое распределение от теоретического отличается достоверно. Тем самым гипотеза об отсутствии этих различий будет опровергнута. Если же χ ² < χ ² (α , df ) , нулевая гипотеза остается в силе. Обычно принято считать допустимым уровень значимости α = 0.05, т. к. в этом случае остается только 5% шансов, что нулевая гипотеза правильна и, следовательно, есть достаточно оснований (95%), чтобы от нее отказаться.
Определенную проблему составляет правильное определение числа степеней свободы (df ), для которых из таблицы берут значения критерия. Для определения числа степеней свободы из общего числа классов k нужно вычесть число ограничений (т. е. число параметров, использованных для расчета теоретических частот).
В зависимости от типа распределения изучаемого признака формула для расчета числа степеней свободы будет меняться. Для альтернативного распределения (k = 2) в расчетах участвует только один параметр (объем выборки), следовательно, число степеней свободы составляет df = k −1=2−1=1. Для полиномиального распределения формула аналогична: df = k −1. Для проверки соответствия вариационного ряда распределению Пуассона используются уже два параметра – объем выборки и среднее значение (численно совпадающее с дисперсией); число степеней свободы df = k −2. При проверке соответствия эмпирического распределения вариант нормальному или биномиальному закону число степеней свободы берется как число фактических классов минус три условия построения рядов – объем выборки, средняя и дисперсия, df = k −3. Сразу стоит отметить, что критерий χ² работает только для выборок объемом не менее 25 вариант , а частоты отдельных классов должны быть не ниже 4 .
Вначале проиллюстрируем применение критерия хи-квадрат на примере анализа альтернативной изменчивости . В одном из опытов по изучению наследственности у томатов было обнаружено 3629 красных и 1176 желтых плодов. Теоретическое соотношение частот при расщеплении признаков во втором гибридном поколении должно быть 3:1 (75% к 25%). Выполняется ли оно? Иными словами, взята ли данная выборка из той генеральной совокупности, в которой соотношение частот 3:1 или 0.75:0.25?
Сформируем таблицу (табл. 4), заполнив значениями эмпирических частот и результатами расчета теоретических частот по формуле:
А = n∙p,
где p – теоретические частости (доли вариант данного типа),
n – объем выборки.
Например, A 2 = n∙p 2 = 4805∙0.25 = 1201.25 ≈ 1201.
Министерство образования и науки Российской Федерации
Федеральное агентство по образованию города Иркутска
Байкальский государственный университет экономики и права
Кафедра Информатики и Кибернетики
Распределение "хи-квадрат" и его применение
Колмыкова Анна Андреевна
студентка 2 курса
группы ИС-09-1
Для обработки полученных данных используем критерий хи-квадрат.
Для этого построим таблицу распределения эмпирических частот, т.е. тех частот, которые мы наблюдаем:
Теоретически, мы ожидаем, что частоты распределятся равновероятно, т.е. частота распределится пропорционально между мальчиками и девочками. Построим таблицу теоретических частот. Для этого умножим сумму по строке на сумму по столбцу и разделим получившееся число на общую сумму (s).
Итоговая таблица для вычислений будет выглядеть так:
χ2 = ∑(Э - Т)² / Т
n = (R - 1), где R – количество строк в таблице.
В нашем случае хи-квадрат = 4,21; n = 2.
По таблице критических значений критерия находим: при n = 2 и уровне ошибки 0,05 критическое значение χ2 = 5,99.
Полученное значение меньше критического, а значит принимается нулевая гипотеза.
Вывод: учителя не придают значение полу ребенка при написании ему характеристики.
Приложение
Критические точки распределения χ2
Таблица 1

Заключение
Студенты почти всех специальностей изучают в конце курса высшей математики раздел "теория вероятностей и математическая статистика", реально они знакомятся лишь с некоторыми основными понятиями и результатами, которых явно не достаточно для практической работы. С некоторыми математическими методами исследования студенты встречаются в специальных курсах (например, таких, как "Прогнозирование и технико-экономическое планирование", "Технико-экономический анализ", "Контроль качества продукции", "Маркетинг", "Контроллинг", "Математические методы прогнозирования", "Статистика" и др. – в случае студентов экономических специальностей), однако изложение в большинстве случаев носит весьма сокращенный и рецептурный характер. В результате знаний у специалистов по прикладной статистике недостаточно.
Поэтому большое значение имеет курс "Прикладная статистика" в технических вузах, а в экономических вузах – курса "Эконометрика", поскольку эконометрика – это, как известно, статистический анализ конкретных экономических данных.
Теория вероятности и математическая статистика дают фундаментальные знания для прикладной статистики и эконометрики.
Они необходимы специалистам для практической работы.
Я рассмотрела непрерывную вероятностную модель и постаралась на примерах показать ее используемость.
Список используемой литературы
1. Орлов А.И. Прикладная статистика. М.: Издательство "Экзамен", 2004.
2. Гмурман В.Е. Теория вероятностей и математическая статистика. М.: Высшая школа, 1999. – 479с.
3. Айвозян С.А. Теория вероятностей и прикладная статистика, т.1. М.: Юнити, 2001. – 656с.
4. Хамитов Г.П., Ведерникова Т.И. Вероятности и статистика. Иркутск: БГУЭП, 2006 – 272с.
5. Ежова Л.Н. Эконометрика. Иркутск: БГУЭП, 2002. – 314с.
6. Мостеллер Ф. Пятьдесят занимательных вероятностных задач с решениями. М. : Наука, 1975. – 111с.
7. Мостеллер Ф. Вероятность. М. : Мир, 1969. – 428с.
8. Яглом А.М. Вероятность и информация. М. : Наука, 1973. – 511с.
9. Чистяков В.П. Курс теории вероятностей. М.: Наука, 1982. – 256с.
10. Кремер Н.Ш. Теория вероятностей и математическая статистика. М.: ЮНИТИ, 2000. – 543с.
11. Математическая энциклопедия, т.1. М.: Советская энциклопедия, 1976. – 655с.
12. http://psystat.at.ua/ - Статистика в психологии и педагогике. Статья Критерий Хи-квадрат.
Критерий независимости хи-квадрат используется для определения связи между двумя категориальными переменными. Примерами пар категориальных переменных являются: Семейное положение vs. Уровень занятости респондента; Порода собак vs. Профессия хозяина, Уровень з/п vs. Специализация инженера и др. При вычислении критерия независимости проверяется гипотеза о том, что между переменными связи нет. Вычисления будем производить с помощью функции MS EXCEL 2010 ХИ2.ТЕСТ() и обычными формулами.
Предположим у нас есть выборка данных, представляющая результат опроса 500 человек. Людям задавалось 2 вопроса: про их семейное положение (женаты, гражданский брак, не состоят в отношениях) и их уровень занятости (полный рабочий день, частичная занятость, временно не работает, на домохозяйстве, на пенсии, учеба). Все ответы поместили в таблицу:
Данная таблица называется таблицей сопряжённости признаков (или факторной таблицей, англ. Contingency table). Элементы на пересечении строк и столбцов таблицы обычно обозначают O ij (от англ. Observed, т.е. наблюденные, фактические частоты).
Нас интересует вопрос «Влияет ли Семейное положение на Занятость?», т.е. существует ли зависимость между двумя методами классификации выборки ?
При проверке гипотез такого вида обычно принимают, что нулевая гипотеза утверждает об отсутствии зависимости способов классификации.
Рассмотрим предельные случаи. Примером полной зависимости двух категориальных переменных является вот такой результат опроса:

В этом случае семейное положение однозначно определяет занятость (см. файл примера лист Пояснение ). И наоборот, примером полной независимости является другой результат опроса:

Обратите внимание, что процент занятости в этом случае не зависит от семейного положения (одинаков для женатых и не женатых). Это как раз совпадает с формулировкой нулевой гипотезы . Если нулевая гипотеза справедлива, то результаты опроса должны были бы так распределиться в таблице, что процент занятых был бы одинаковым независимо от семейного положения. Используя это, вычислим результаты опроса, которые соответствуют нулевой гипотезе (см. файл примера лист Пример ).
Сначала вычислим оценку вероятности, того, что элемент выборки будет иметь определенную занятость (см. столбец u i):

где с – количество столбцов (columns), равное количеству уровней переменной «Семейное положение».
Затем вычислим оценку вероятности, того, что элемент выборки будет иметь определенное семейное положение (см. строку v j).

где r – количество строк (rows), равное количеству уровней переменной «Занятость».
Теоретическая частота для каждой ячейки E ij (от англ. Expected, т.е. ожидаемая частота) в случае независимости переменных вычисляется по формуле:
E ij =n* u i * v j

Известно, что статистика Х 2 0 при больших n имеет приблизительно с (r-1)(c-1) степенями свободы (df – degrees of freedom):

Если вычисленное на основе выборки значение этой статистики «слишком большое» (больше порогового), то нулевая гипотеза отвергается. Пороговое значение вычисляется на основании , например с помощью формулы =ХИ2.ОБР.ПХ(0,05; df) .
Примечание : Уровень значимости обычно принимается равным 0,1; 0,05; 0,01.
При проверке гипотезы также удобно вычислять , которое мы сравниваем с уровнем значимости . p -значение рассчитывается с использованием с (r-1)*(c-1)=df степеней свободы.
Если вероятность, того что случайная величина имеющая с (r-1)(c-1) степенями свободы примет значение больше вычисленной статистики Х 2 0 , т.е. P{Х 2 (r-1)*(c-1) >Х 2 0 }, меньше уровня значимости , то нулевая гипотеза отклоняется.
В MS EXCEL p-значение можно вычислить с помощью формулы =ХИ2.РАСП.ПХ(Х 2 0 ;df) , конечно, вычислив непосредственно перед этим значение статистики Х 2 0 (это сделано в файле примера ). Однако, удобнее всего воспользоваться функцией ХИ2.ТЕСТ() . В качестве аргументов этой функции указываются ссылки на диапазоны содержащие фактические (Observed) и вычисленные теоретические частоты (Expected).
Если уровень значимости > p -значения , то означает это фактические и теоретические частоты, вычисленные из предположения справедливости нулевой гипотезы , серьезно отличаются. Поэтому, нулевую гипотезу нужно отклонить.
Использование функции ХИ2.ТЕСТ() позволяет ускорить процедуру проверки гипотез , т.к. не нужно вычислять значение статистики . Теперь достаточно сравнить результат функции ХИ2.ТЕСТ() с заданным уровнем значимости .
Примечание : Функция ХИ2.ТЕСТ() , английское название CHISQ.TEST, появилась в MS EXCEL 2010. Ее более ранняя версия ХИ2ТЕСТ() , доступная в MS EXCEL 2007 имеет тот же функционал. Но, как и для ХИ2.ТЕСТ() , теоретические частоты нужно вычислить самостоятельно.