Variabile casuale è una variabile che può assumere determinati valori a seconda delle varie circostanze, e variabile casuale è chiamata continua , se può assumere qualsiasi valore da un intervallo limitato o illimitato. Per una variabile casuale continua, è impossibile specificare tutti i valori possibili, pertanto vengono indicati gli intervalli di questi valori associati a determinate probabilità.
Esempi di variabili casuali continue sono: il diametro di una parte trasformata in una data dimensione, l'altezza di una persona, la portata di un proiettile, ecc.
Poiché per variabili casuali continue la funzione F(X), A differenza di variabili casuali discrete, non ha salti da nessuna parte, allora la probabilità di ogni singolo valore di una variabile casuale continua è uguale a zero.
Ciò significa che per una variabile casuale continua non ha senso parlare di distribuzione di probabilità tra i suoi valori: ognuno di essi ha probabilità zero. Tuttavia, in un certo senso, tra i valori di una variabile aleatoria continua ci sono "più e meno probabili". Ad esempio, è improbabile che qualcuno dubiti che il valore di una variabile casuale - l'altezza di una persona incontrata casualmente - 170 cm - sia più probabile di 220 cm, sebbene l'uno e l'altro valore possano verificarsi nella pratica.
Funzione di distribuzione di una variabile casuale continua e densità di probabilità
Come legge di distribuzione, che ha senso solo per variabili aleatorie continue, viene introdotto il concetto di densità di distribuzione o densità di probabilità. Affrontiamolo confrontando il significato della funzione di distribuzione per una variabile aleatoria continua e per una variabile aleatoria discreta.
Quindi, la funzione di distribuzione di una variabile casuale (sia discreta che continua) o funzione integraleè chiamata una funzione che determina la probabilità che il valore di una variabile casuale X minore o uguale al valore limite X.
Per una variabile casuale discreta nei punti dei suoi valori X1 , X 2 , ..., X io ,... masse concentrate di probabilità p1 , p 2 , ..., p io ,..., e la somma di tutte le masse è uguale a 1. Trasferiamo questa interpretazione al caso di una variabile casuale continua. Immagina che una massa uguale a 1 non sia concentrata in punti separati, ma sia continuamente "spalmata" lungo l'asse x Bue con una densità irregolare. La probabilità di colpire una variabile casuale su qualsiasi sito Δ X sarà interpretato come la massa attribuibile a questa sezione e la densità media in questa sezione - come il rapporto tra massa e lunghezza. Abbiamo appena introdotto un concetto importante nella teoria della probabilità: la densità di distribuzione.
Densità di probabilità f(X) di una variabile casuale continua è la derivata della sua funzione di distribuzione:
![]() .
.
Conoscendo la funzione di densità, possiamo trovare la probabilità che il valore di una variabile casuale continua appartenga all'intervallo chiuso [ un; b]:

la probabilità che una variabile casuale continua X prenderà qualsiasi valore dall'intervallo [ un; b], è uguale a un certo integrale della sua densità di probabilità nell'intervallo da un prima b:
![]()
![]() .
.
In questo caso, la formula generale della funzione F(X) la distribuzione di probabilità di una variabile casuale continua, che può essere utilizzata se si conosce la funzione di densità f(X) :
![]() .
.
Il grafico della densità di probabilità di una variabile casuale continua è chiamato curva di distribuzione (fig. sotto).

L'area della figura (ombreggiata nella figura), delimitata da una curva, linee rette tracciate da punti un e b perpendicolare all'asse delle ascisse e all'asse Oh, visualizza graficamente la probabilità che il valore di una variabile casuale continua Xè nel range di un prima b.
Proprietà della funzione di densità di probabilità di una variabile casuale continua
1. La probabilità che una variabile casuale assuma qualsiasi valore dall'intervallo (e l'area della figura, che è limitata dal grafico della funzione f(X) e asse Oh) è uguale a uno:
2. La funzione di densità di probabilità non può assumere valori negativi:
e al di fuori dell'esistenza della distribuzione, il suo valore è zero
Densità di distribuzione f(X), così come la funzione di distribuzione F(X), è una delle forme della legge di distribuzione, ma a differenza della funzione di distribuzione, non è universale: la densità di distribuzione esiste solo per variabili aleatorie continue.
Citiamo i due tipi più importanti nella pratica di distribuzione di una variabile casuale continua.
Se la funzione di densità di distribuzione f(X) una variabile casuale continua in un intervallo finito [ un; b] assume un valore costante C, e al di fuori dell'intervallo assume un valore uguale a zero, quindi questo distribuzione è chiamata uniforme .
Se il grafico della funzione di densità di distribuzione è simmetrico rispetto al centro, i valori medi sono concentrati vicino al centro e quando ci si allontana dal centro vengono raccolti più diversi dalle medie (il grafico della funzione assomiglia a un taglio di un campanello), poi questo distribuzione è chiamata normale .
Esempio 1 La funzione di distribuzione di probabilità di una variabile casuale continua è nota:
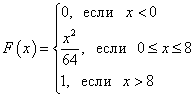
Trova una caratteristica f(X) la densità di probabilità di una variabile casuale continua. Tracciare grafici per entrambe le funzioni. Trova la probabilità che una variabile casuale continua assuma qualsiasi valore nell'intervallo da 4 a 8: .
Soluzione. Otteniamo la funzione di densità di probabilità trovando la derivata della funzione di distribuzione di probabilità:

Grafico delle funzioni F(X) - parabola:

Grafico delle funzioni f(X) - retta:

Troviamo la probabilità che una variabile casuale continua assuma un valore compreso tra 4 e 8:
Esempio 2 La funzione di densità di probabilità di una variabile casuale continua è data come:

Calcola fattore C. Trova una caratteristica F(X) la distribuzione di probabilità di una variabile casuale continua. Tracciare grafici per entrambe le funzioni. Trova la probabilità che una variabile casuale continua assuma qualsiasi valore nell'intervallo da 0 a 5: .
Soluzione. Coefficiente C troviamo, utilizzando la proprietà 1 della funzione di densità di probabilità:

Pertanto, la funzione di densità di probabilità di una variabile casuale continua è:

Integrando troviamo la funzione F(X) distribuzioni di probabilità. Se una X < 0 , то F(X) = 0. Se 0< X < 10 , то
![]() .
.
X> 10, quindi F(X) = 1 .
Pertanto, il record completo della funzione di distribuzione di probabilità è:

Grafico delle funzioni f(X) :

Grafico delle funzioni F(X) :

Troviamo la probabilità che una variabile casuale continua assuma un valore compreso tra 0 e 5:
Esempio 3 Densità di probabilità di una variabile casuale continua Xè data dall'uguaglianza , mentre . Trova il coefficiente MA, la probabilità che sia una variabile casuale continua X prende un valore dall'intervallo ]0, 5[, la funzione di distribuzione di una variabile casuale continua X.
Soluzione. Per condizione, si arriva all'uguaglianza

Pertanto, da dove . Così,
![]() .
.
Ora troviamo la probabilità che sia una variabile casuale continua X prenderà qualsiasi valore dall'intervallo ]0, 5[:

Ora otteniamo la funzione di distribuzione di questa variabile casuale:

Esempio 4 Trova la densità di probabilità di una variabile casuale continua X, che accetta solo valori non negativi e la sua funzione di distribuzione ![]() .
.
1.2.4. Variabili casuali e loro distribuzioni
Distribuzioni di variabili casuali e funzioni di distribuzione. La distribuzione di una variabile casuale numerica è una funzione che determina in modo univoco la probabilità che una variabile casuale assuma un dato valore o appartenga a un determinato intervallo.
Il primo è se la variabile casuale assume un numero finito di valori. Allora la distribuzione è data dalla funzione P(X = x), dando ogni possibile valore X variabile casuale X la probabilità che X = x.
Il secondo è se la variabile casuale assume infiniti valori. Ciò è possibile solo quando lo spazio di probabilità su cui è definita la variabile aleatoria è costituito da un numero infinito di eventi elementari. Quindi la distribuzione è data dall'insieme delle probabilità Papà <
X
Papà <
X
Questa relazione mostra che proprio come la distribuzione può essere calcolata dalla funzione di distribuzione, così, al contrario, la funzione di distribuzione può essere calcolata dalla distribuzione.
Le funzioni di distribuzione utilizzate nei metodi decisionali probabilistico-statistici e in altre ricerche applicate sono discrete o continue o loro combinazioni.
Le funzioni di distribuzione discrete corrispondono a variabili casuali discrete che prendono un numero finito di valori o valori da un insieme i cui elementi possono essere rinumerati con numeri naturali (tali insiemi sono chiamati numerabili in matematica). Il loro grafico sembra una scala a pioli (Fig. 1).
Esempio 1 Numero X degli articoli difettosi nel lotto assume il valore 0 con probabilità 0,3, il valore 1 con probabilità 0,4, il valore 2 con probabilità 0,2 e il valore 3 con probabilità 0,1. Grafico della funzione di distribuzione di una variabile casuale X mostrato in Fig.1.
Fig. 1. Grafico della funzione di distribuzione del numero di prodotti difettosi.
Le funzioni di distribuzione continua non hanno salti. Aumentano in modo monotono all'aumentare dell'argomento, da 0 per a 1 per . Le variabili casuali con funzioni di distribuzione continua sono dette continue.
Le funzioni di distribuzione continua utilizzate nei metodi decisionali probabilistico-statistici hanno derivate. Prima derivata f(x) funzioni di distribuzione F(x)è chiamata densità di probabilità,
La funzione di distribuzione può essere determinata dalla densità di probabilità:
![]()
Per qualsiasi funzione di distribuzione
Le proprietà elencate delle funzioni di distribuzione sono costantemente utilizzate nei metodi decisionali probabilistico-statistici. In particolare, l'ultima uguaglianza implica una forma specifica delle costanti nelle formule per le densità di probabilità considerate di seguito.
Esempio 2 Viene spesso utilizzata la seguente funzione di distribuzione:
 (1)
(1)
dove un e b- alcuni numeri un . Troviamo la densità di probabilità di questa funzione di distribuzione:

(a punti x = a e x = b derivata di funzione F(x) non esiste).
Una variabile casuale con funzione di distribuzione (1) è chiamata "uniformemente distribuita sull'intervallo [ un; b]».
Le funzioni di distribuzione mista si verificano, in particolare, quando le osservazioni si fermano a un certo punto. Ad esempio, quando si analizzano i dati statistici ottenuti utilizzando piani di test di affidabilità che prevedono la fine dei test dopo un certo periodo di tempo. O quando si analizzano i dati sui prodotti tecnici che hanno richiesto riparazioni in garanzia.
Esempio 3 Sia, ad esempio, la vita utile di una lampadina elettrica una variabile casuale con una funzione di distribuzione F(t), e la prova viene eseguita fino all'avaria della lampadina, se questa avviene a meno di 100 ore dall'inizio della prova, oppure fino al momento t0= 100 ore. Permettere G(t)- funzione di distribuzione del tempo di funzionamento della lampada in buone condizioni in questo test. Quindi

Funzione G(t) ha un salto in un punto t0, poiché la variabile casuale corrispondente assume il valore t0 con probabilità 1- F(t0)> 0.
Caratteristiche delle variabili casuali. Nei metodi decisionali probabilistico-statistici vengono utilizzate alcune caratteristiche delle variabili casuali, espresse attraverso funzioni di distribuzione e densità di probabilità.
Quando si descrive la differenziazione del reddito, quando si trovano limiti di confidenza per i parametri delle distribuzioni di variabili casuali, e in molti altri casi, viene utilizzato un concetto come "quantile d'ordine". R", dove 0< p < 1 (обозначается x pag). Ordine quantile Rè il valore di una variabile casuale per la quale la funzione di distribuzione assume il valore R oppure c'è un "salto" da un valore inferiore a R fino ad un valore maggiore R(Fig. 2). Può succedere che questa condizione sia soddisfatta per tutti i valori di x appartenenti a questo intervallo (cioè, la funzione di distribuzione è costante su questo intervallo ed è uguale a R). Quindi ciascuno di questi valori è chiamato "quantile dell'ordine R". Per le funzioni di distribuzione continua, di regola, esiste un singolo quantile x pag ordine R(Fig. 2), e
F(xp) = p. (2)

Fig.2. Definizione di quantile x pag ordine R.
Esempio 4 Troviamo il quantile x pag ordine R per la funzione di distribuzione F(x) da (1).
A 0< p < 1 квантиль x pag si trova dall'equazione
quelli. x pag = a + p(b – a) = a( 1- p)+bp. In p= 0 qualsiasi X < unè il quantile dell'ordine p= 0. Quantile d'ordine p= 1 è un numero qualsiasi X > b.
Per le distribuzioni discrete, di regola, non esiste x pag equazione soddisfacente (2). Più precisamente, se la distribuzione di una variabile aleatoria è riportata nella Tabella 1, dove x 1< x 2 < … < x k , quindi l'uguaglianza (2), considerata come un'equazione rispetto a x pag, ha soluzioni solo per K i valori p, vale a dire,
p \u003d p 1,
p \u003d p 1 + p 2,
p \u003d p 1 + p 2 + p 3,
p \u003d p 1 + p 2 + ...+ pm, 3 < m < K,
p = p 1 + p 2 + … + p k.
Tabella 1.
Distribuzione di una variabile casuale discreta
Per l'elenco K valori di probabilità p soluzione x pag l'equazione (2) non è unica, vale a dire,
F(x) = p 1 + p 2 + ... + p m
per tutti X tale che x m< x < xm+1 . Quelli. x p - qualsiasi numero dall'intervallo (x m ; x m+1 ]. Per tutti gli altri R dall'intervallo (0;1) non compreso nell'elenco (3), si ha un “salto” da un valore inferiore a R fino ad un valore maggiore R. Vale a dire, se
p 1 + p 2 + … + p m
poi x p \u003d x m + 1.
La proprietà considerata delle distribuzioni discrete crea notevoli difficoltà nella tabulazione e nell'utilizzo di tali distribuzioni, poiché risulta impossibile mantenere con precisione i valori numerici tipici delle caratteristiche della distribuzione. In particolare, ciò vale per i valori critici e i livelli di significatività dei test statistici non parametrici (vedi sotto), poiché le distribuzioni delle statistiche di questi test sono discrete.
Il quantile d'ordine è di grande importanza in statistica. R= ½. Si chiama mediana (variabile casuale X o la sua funzione di distribuzione F(x)) e indicato Io(X). In geometria, c'è il concetto di "mediana" - una linea retta che passa per il vertice di un triangolo e divide a metà il suo lato opposto. Nella statistica matematica, la mediana non divide in due il lato del triangolo, ma la distribuzione di una variabile casuale: l'uguaglianza F(x0.5)= 0,5 significa che la probabilità di andare a sinistra x0,5 e la probabilità di ottenere ragione x0,5(o direttamente a x0,5) sono uguali tra loro e uguali a ½, cioè
P(X < X 0,5) = P(X > X 0,5) = ½.
La mediana indica il "centro" della distribuzione. Dal punto di vista di uno dei concetti moderni - la teoria delle procedure statistiche stabili - la mediana è una caratteristica migliore di una variabile casuale rispetto all'aspettativa matematica. Quando si elaborano i risultati della misurazione in una scala ordinale (vedere il capitolo sulla teoria della misurazione), è possibile utilizzare la mediana, ma non l'aspettativa matematica.
Una tale caratteristica di una variabile casuale come una modalità ha un significato chiaro: il valore (o i valori) di una variabile casuale corrispondente a un massimo locale della densità di probabilità per una variabile casuale continua o un massimo locale della probabilità per una variabile casuale discreta variabile.
Se una x0è il modo di una variabile casuale con densità f(x), quindi, come è noto dal calcolo differenziale, .
Una variabile casuale può avere molte modalità. Quindi, per distribuzione uniforme (1) ogni punto X tale che un< x < b , è la moda. Tuttavia, questa è un'eccezione. La maggior parte delle variabili casuali utilizzate nei metodi decisionali probabilistico-statistici e in altre ricerche applicate hanno una modalità. Le variabili casuali, le densità, le distribuzioni che hanno una modalità sono dette unimodali.
L'aspettativa matematica per variabili casuali discrete con un numero finito di valori è considerata nel capitolo "Eventi e probabilità". Per una variabile casuale continua X valore atteso M(X) soddisfa l'uguaglianza
![]()
che è un analogo della formula (5) dell'affermazione 2 del capitolo "Eventi e probabilità".
Esempio 5 Aspettativa matematica per una variabile aleatoria uniformemente distribuita Xè uguale a
Per le variabili casuali considerate in questo capitolo, sono vere tutte quelle proprietà delle aspettative e varianze matematiche che sono state considerate in precedenza per variabili casuali discrete con un numero finito di valori. Tuttavia, non forniamo prove di queste proprietà, poiché richiedono l'approfondimento delle sottigliezze matematiche, il che non è necessario per la comprensione e l'applicazione qualificata dei metodi decisionali probabilistico-statistici.
Commento. In questo libro di testo vengono volutamente evitate sottigliezze matematiche, connesse, in particolare, con i concetti di insiemi misurabili e di funzioni misurabili, l'algebra degli eventi e così via. Coloro che desiderano padroneggiare questi concetti dovrebbero fare riferimento alla letteratura specializzata, in particolare all'enciclopedia.
Ciascuna delle tre caratteristiche - aspettativa matematica, mediana, moda - descrive il "centro" della distribuzione di probabilità. Il concetto di "centro" può essere definito in diversi modi, da qui le tre diverse caratteristiche. Tuttavia, per un'importante classe di distribuzioni - unimodale simmetrica - tutte e tre le caratteristiche coincidono.
Densità di distribuzione f(x)è la densità della distribuzione simmetrica, se esiste un numero x 0 tale che
![]() . (3)
. (3)
Uguaglianza (3) significa che il grafico della funzione y = f(x) simmetrico rispetto ad una linea verticale passante per il centro di simmetria X = X 0. Dalla (3) segue che la funzione di distribuzione simmetrica soddisfa la relazione
![]() (4)
(4)
Per una distribuzione simmetrica con un modo, la media, la mediana e il modo sono uguali e uguali x 0.
Il caso più importante è la simmetria rispetto a 0, cioè x 0= 0. Allora (3) e (4) diventano uguaglianze
![]() (6)
(6)
rispettivamente. Le relazioni di cui sopra mostrano che non è necessario tabulare distribuzioni simmetriche per tutti X, è sufficiente avere tabelle per X > x0.
Notiamo un'altra proprietà delle distribuzioni simmetriche, che viene costantemente utilizzata nei metodi decisionali probabilistico-statistici e in altre ricerche applicate. Per una funzione di distribuzione continua
P(|X| < a) = P(-a < X < a) = F(a) – F(-a),
dove Fè la funzione di distribuzione della variabile casuale X. Se la funzione di distribuzione Fè simmetrico rispetto a 0, cioè allora vale la formula (6).
P(|X| < a) = 2F(a) – 1.
Viene spesso utilizzata un'altra formulazione dell'affermazione in esame: se
![]() .
.
Se e sono quantili dell'ordine e, rispettivamente (vedi (2)) di una funzione di distribuzione simmetrica rispetto a 0, allora dalla (6) segue che
Dalle caratteristiche della posizione - l'aspettativa matematica, mediana, moda - passiamo alle caratteristiche dello spread di una variabile casuale X: varianza, deviazione standard e coefficiente di variazione v. La definizione e le proprietà della varianza per variabili casuali discrete sono state considerate nel capitolo precedente. Per variabili casuali continue
La deviazione standard è il valore non negativo della radice quadrata della varianza:
Il coefficiente di variazione è il rapporto tra la deviazione standard e l'aspettativa matematica:
Il coefficiente di variazione si applica quando M(X)> 0. Misura lo spread in unità relative, mentre la deviazione standard è in unità assolute.
Esempio 6 Per una variabile casuale distribuita uniformemente X trovare la varianza, la deviazione standard e il coefficiente di variazione. La dispersione è:

La sostituzione delle variabili permette di scrivere:
dove c = (b – un)/ 2. Pertanto, la deviazione standard è uguale e il coefficiente di variazione è:
Per ogni variabile casuale X determinare altre tre quantità - centrate Y, normalizzato V e dato u. Variabile casuale centrata Yè la differenza tra la variabile casuale data X e la sua aspettativa matematica M(X), quelli. Y = X - M(X). Aspettativa matematica di una variabile casuale centrata Yè uguale a 0 e la varianza è la varianza della variabile casuale data: M(Y) = 0, D(Y) = D(X). funzione di distribuzione F Y(X) variabile casuale centrata Y relativi alla funzione di distribuzione F(X) variabile casuale iniziale X rapporto:
F Y(X) = F(X + M(X)).
Per le densità di queste variabili casuali, l'uguaglianza
fY(X) = f(X + M(X)).
Variabile casuale normalizzata Vè il rapporto di questa variabile casuale X alla sua deviazione standard, cioè . Aspettativa matematica e varianza di una variabile casuale normalizzata V espresso attraverso le caratteristiche X Così:
![]() ,
,
dove vè il coefficiente di variazione della variabile casuale originale X. Per la funzione di distribuzione FV(X) e densità f V(X) variabile casuale normalizzata V noi abbiamo:
dove F(X) è la funzione di distribuzione della variabile casuale originale X, un f(X) è la sua densità di probabilità.
Variabile casuale ridotta uè una variabile casuale centrata e normalizzata:
![]() .
.
Per una variabile casuale ridotta
Le variabili casuali normalizzate, centrate e ridotte sono costantemente utilizzate sia nella ricerca teorica che negli algoritmi, nei prodotti software, nella documentazione normativa e tecnica e istruttiva e metodologica. In particolare, perché le uguaglianze ![]() consentono di semplificare la convalida di metodi, le formulazioni di teoremi e le formule di calcolo.
consentono di semplificare la convalida di metodi, le formulazioni di teoremi e le formule di calcolo.
Vengono utilizzate trasformazioni di variabili casuali e piani più generali. Quindi se Y = ascia + b, dove un e b sono alcuni numeri, quindi
Esempio 7 Se poi Yè la variabile casuale ridotta e le formule (8) vengono trasformate in formule (7).
Con ogni variabile casuale X puoi collegare molte variabili casuali Y dato dalla formula Y = ascia + b a vari un> 0 e b. Questo set è chiamato famiglia del cambio di scala, generato da una variabile casuale X. Funzioni di distribuzione F Y(X) costituiscono una famiglia di distribuzioni con scalabilità generata dalla funzione di distribuzione F(X). Invece di Y = ascia + b notazione di uso frequente
![]()
Numero Insieme aè chiamato parametro shift e numero d- parametro di scala. La formula (9) lo mostra X- il risultato della misurazione di una certa quantità - entra In- il risultato della misura di pari valore, se l'inizio della misura viene spostato nel punto Insieme a, quindi utilizzare la nuova unità di misura, in d volte maggiore di quello vecchio.
Per la famiglia scale-shift (9), la distribuzione X è chiamata standard. Nei metodi decisionali probabilistico-statistici e in altre ricerche applicate, vengono utilizzate la distribuzione normale standard, la distribuzione standard di Weibull-Gnedenko, la distribuzione gamma standard, ecc. (vedi sotto).
Vengono utilizzate anche altre trasformazioni di variabili casuali. Ad esempio, per una variabile casuale positiva X ritenere Y= registro X, dove lg Xè il logaritmo decimale del numero X. Catena di uguaglianze
F Y (x) = P( lg X< x) = P(X < 10x) = F( 10X)
mette in relazione le funzioni di distribuzione X e Y.
Durante l'elaborazione dei dati, vengono utilizzate tali caratteristiche di una variabile casuale X come momenti di ordine q, cioè. aspettative matematiche di una variabile casuale Xq, q= 1, 2, … Quindi, l'aspettativa matematica stessa è un momento dell'ordine 1. Per una variabile casuale discreta, il momento dell'ordine q può essere calcolato come
![]()
Per una variabile casuale continua
![]()
Momenti di ordine q chiamati anche i momenti iniziali dell'ordine q, in contrasto con le caratteristiche correlate - i momenti centrali dell'ordine q, dato dalla formula
Pertanto, la dispersione è un momento centrale dell'ordine 2.
Distribuzione normale e teorema del limite centrale. Nei metodi decisionali probabilistico-statistici si parla spesso di distribuzione normale. A volte cercano di usarlo per modellare la distribuzione dei dati iniziali (questi tentativi non sono sempre giustificati - vedi sotto). Ancora più importante, molti metodi di elaborazione dei dati si basano sul fatto che i valori calcolati hanno distribuzioni vicine alla normalità.
Permettere X 1 , X 2 ,…, X n M(X i) = m e dispersioni D(X i) = , io = 1, 2,…, n,... Come risulta dai risultati del capitolo precedente,
Considera la variabile casuale ridotta unn per la somma ![]() , vale a dire,
, vale a dire,
![]()
Come segue dalle formule (7), M(unn) = 0, D(unn) = 1.
(per termini distribuiti in modo identico). Permettere X 1 , X 2 ,…, X n, … sono variabili casuali indipendenti distribuite in modo identico con aspettative matematiche M(X i) = m e dispersioni D(X i) = , io = 1, 2,…, n,... Allora per ogni x c'è un limite
![]()
dove F(x)è la funzione di distribuzione normale standard.
Maggiori informazioni sulla funzione F(x) - sotto (si legge “fi da x”, perché F- Lettera maiuscola greca "phi").
Il teorema del limite centrale (CLT) prende il nome dal fatto che è il risultato matematico centrale, più frequentemente utilizzato, della teoria della probabilità e della statistica matematica. La storia del CLT dura circa 200 anni - dal 1730, quando il matematico inglese A. De Moivre (1667-1754) pubblicò il primo risultato relativo al CLT (vedi sotto sul teorema di Moivre-Laplace), fino agli anni venti - trenta del XX secolo, quando Finn J.W. Lindeberg, francese Paul Levy (1886-1971), jugoslavo V. Feller (1906-1970), russo A.Ya. Khinchin (1894-1959) e altri scienziati ottennero condizioni necessarie e sufficienti per la validità del classico teorema del limite centrale.
Lo sviluppo dell'argomento in esame non si è fermato qui: hanno studiato variabili casuali che non hanno dispersione, ad es. quelli per chi
![]()
(accademico B.V. Gnedenko e altri), la situazione in cui vengono sommate variabili casuali (più precisamente, elementi casuali) di natura più complessa rispetto ai numeri (accademici Yu.V. Prokhorov, A.A. Borovkov e loro associati), ecc. .d.
funzione di distribuzione F(x)è data dall'uguaglianza
![]() ,
,
dove è la densità della distribuzione normale standard, che ha un'espressione piuttosto complicata:
![]() .
.
Qui \u003d 3.1415925 ... è un numero noto in geometria, uguale al rapporto tra la circonferenza e il diametro, e \u003d 2.718281828 ... - la base dei logaritmi naturali (per ricordare questo numero, si noti che il 1828 è l'anno di nascita dello scrittore Leo Tolstoj). Come è noto dall'analisi matematica,
![]()
Quando si elaborano i risultati delle osservazioni, la funzione di distribuzione normale non viene calcolata secondo le formule precedenti, ma si trova utilizzando tabelle speciali o programmi per computer. Le migliori "tabelle di statistica matematica" russe sono state compilate dai membri corrispondenti dell'Accademia delle scienze dell'URSS L.N. Bolshev e N.V. Smirnov.
La forma della densità della distribuzione normale standard deriva dalla teoria matematica, che non possiamo qui considerare, così come dalla dimostrazione del CLT.
A titolo illustrativo, presentiamo piccole tabelle della funzione di distribuzione F(x)(Tabella 2) e suoi quantili (Tabella 3). Funzione F(x)è simmetrico rispetto a 0, che si riflette nelle Tabelle 2-3.
Tavolo 2.
Funzione della distribuzione normale standard.
Se la variabile casuale X ha una funzione di distribuzione F(x), poi M(X) = 0, D(X) = 1. Questa affermazione è dimostrata nella teoria della probabilità basata sulla forma della densità di probabilità. È d'accordo con un'affermazione simile per le caratteristiche della variabile casuale ridotta unn, il che è del tutto naturale, poiché il CLT afferma che con un aumento infinito del numero di termini, la funzione di distribuzione unn tende alla funzione di distribuzione normale standard F(x), e per qualsiasi X.
Tabella 3
Quantili della distribuzione normale standard.
Ordine quantile R |
Ordine quantile R |
||
Introduciamo il concetto di famiglia di distribuzioni normali. Per definizione, una distribuzione normale è la distribuzione di una variabile casuale X, per cui la distribuzione della variabile casuale ridotta è F(x). Come segue dalle proprietà generali delle famiglie di distribuzioni scale-shift (vedi sopra), la distribuzione normale è la distribuzione di una variabile casuale
dove Xè una variabile casuale con distribuzione F(X), e m = M(Y), = D(Y). Distribuzione normale con parametri di spostamento m e la scala è solitamente indicata N(m, ) (a volte la notazione N(m, ) ).
Come segue da (8), la densità di probabilità della distribuzione normale N(m, ) c'è

Le distribuzioni normali formano una famiglia di scale-shift. In questo caso, il parametro di scala è d= 1/ e il parametro di spostamento c = - m/ .
Per i momenti centrali del terzo e quarto ordine della distribuzione normale, le uguaglianze sono vere
![]()
Queste uguaglianze sono alla base dei metodi classici per verificare che i risultati delle osservazioni seguano una distribuzione normale. Al momento, si raccomanda di solito di verificare la normalità mediante il criterio w Shapiro - Wilka. Il problema del controllo di normalità è discusso di seguito.
Se variabili casuali X 1 e X 2 hanno funzioni di distribuzione N(m 1
, 1)
e N(m 2
, 2)
rispettivamente, quindi X 1+ X 2 ha una distribuzione ![]() Pertanto, se le variabili casuali X 1
,
X 2
,…,
X n N(m, )
, quindi la loro media aritmetica
Pertanto, se le variabili casuali X 1
,
X 2
,…,
X n N(m, )
, quindi la loro media aritmetica
![]()
ha una distribuzione N(m, ) . Queste proprietà della distribuzione normale sono costantemente utilizzate in vari metodi decisionali probabilistico-statistici, in particolare nel controllo statistico dei processi tecnologici e nel controllo statistico di accettazione mediante un attributo quantitativo.
La distribuzione normale definisce tre distribuzioni che ora vengono spesso utilizzate nell'elaborazione dei dati statistici.
Distribuzione (chi - quadrato) - distribuzione di una variabile casuale
dove variabili casuali X 1 , X 2 ,…, X n sono indipendenti e hanno la stessa distribuzione N(0,1). In questo caso, il numero di termini, ad es. n, è chiamato il "numero di gradi di libertà" della distribuzione chi-quadrato.
Distribuzione t Student è la distribuzione di una variabile casuale
dove variabili casuali u e X indipendente, u ha una distribuzione normale standard N(0,1) e X– distribuzione chi – quadrato con n gradi di libertà. in cui nè chiamato il "numero di gradi di libertà" della distribuzione di Student. Questa distribuzione fu introdotta nel 1908 dallo statistico inglese W. Gosset, che lavorava in una fabbrica di birra. I metodi probabilistico-statistici sono stati utilizzati per prendere decisioni economiche e tecniche in questa fabbrica, quindi la sua direzione ha vietato a V. Gosset di pubblicare articoli scientifici a proprio nome. In questo modo veniva protetto un segreto commerciale, il "saper fare" sotto forma di metodi probabilistico-statistici sviluppati da W. Gosset. Tuttavia, è stato in grado di pubblicare sotto lo pseudonimo di "Studente". La storia di Gosset-Student mostra che per altri cento anni la grande efficienza economica dei metodi decisionali probabilistico-statistici è stata ovvia per i manager britannici.
La distribuzione di Fisher è la distribuzione di una variabile casuale
dove variabili casuali X 1 e X 2 sono indipendenti e hanno distribuzioni chi - il quadrato con il numero di gradi di libertà K 1 e K 2 rispettivamente. Allo stesso tempo, una coppia (K 1 , K 2 ) è una coppia di "numeri di gradi di libertà" della distribuzione di Fisher, vale a dire, K 1 è il numero di gradi di libertà del numeratore, e K 2 è il numero di gradi di libertà del denominatore. La distribuzione della variabile casuale F prende il nome dal grande statistico inglese R. Fisher (1890-1962), che la utilizzò attivamente nel suo lavoro.
Espressioni per le funzioni di distribuzione di chi quadrato, Student e Fisher, le loro densità e caratteristiche, nonché le tabelle possono essere trovate nella letteratura speciale (vedi, ad esempio,).
Come già notato, le distribuzioni normali sono attualmente spesso utilizzate nei modelli probabilistici in vari campi applicati. Perché questa famiglia di distribuzioni a due parametri è così diffusa? È chiarito dal seguente teorema.
Teorema del limite centrale(per termini distribuiti in modo diverso). Permettere X 1 , X 2 ,…, X n,... sono variabili casuali indipendenti con aspettative matematiche M(X 1 ), M(X 2 ),…, M(X n), … e dispersioni D(X 1 ), D(X 2 ),…, D(X n), … rispettivamente. Permettere
Quindi, sotto la validità di determinate condizioni che garantiscono l'esiguità del contributo di uno qualsiasi dei termini a unn,
![]()
per chiunque X.
Le condizioni in questione non verranno qui formulate. Possono essere trovati nella letteratura specializzata (vedi, ad esempio,). "Chiarire le condizioni in cui opera il CPT è merito degli eccezionali scienziati russi A.A. Markov (1857-1922) e, in particolare, A.M. Lyapunov (1857-1918)" .
Il teorema del limite centrale mostra che nel caso in cui il risultato di una misurazione (osservazione) si forma sotto l'influenza di molte ragioni, ognuna delle quali fornisce solo un piccolo contributo, e il risultato cumulativo è determinato da in modo additivo, cioè. per aggiunta, la distribuzione del risultato della misurazione (osservazione) è quasi normale.
A volte si ritiene che affinché la distribuzione sia normale sia sufficiente che il risultato della misurazione (osservazione) X formato sotto l'influenza di molte cause, ognuna delle quali ha un piccolo effetto. Questo non è vero. Ciò che conta è come funzionano queste cause. Se additivo, allora X ha una distribuzione approssimativamente normale. Se una moltiplicativamente(cioè le azioni delle singole cause si moltiplicano, non si sommano), quindi la distribuzione X non vicino alla normalità, ma al cosiddetto. logaritmicamente normale, cioè non X, e lg X ha una distribuzione approssimativamente normale. Se non c'è motivo di ritenere che uno di questi due meccanismi per la formazione del risultato finale (o qualche altro meccanismo ben definito) sia in funzione, allora sulla distribuzione X non si può dire nulla di preciso.
Da quanto detto ne consegue che in uno specifico problema applicato, la normalità dei risultati delle misurazioni (osservazioni), di regola, non può essere stabilita da considerazioni generali, va verificata con criteri statistici. Oppure utilizzare metodi statistici non parametrici che non si basano su ipotesi sull'appartenenza delle funzioni di distribuzione dei risultati delle misurazioni (osservazioni) all'una o all'altra famiglia parametrica.
Distribuzioni continue utilizzate nei metodi decisionali probabilistico-statistici. Oltre alla famiglia di scalabilità delle distribuzioni normali, sono ampiamente utilizzate numerose altre famiglie di distribuzione: distribuzioni logaritmicamente normali, esponenziali, Weibull-Gnedenko, gamma. Diamo un'occhiata a queste famiglie.
Valore casuale X ha una distribuzione log-normale se la variabile casuale Y= registro X ha una distribuzione normale. Quindi Z=ln X = 2,3026…Y ha anche una distribuzione normale N(un 1 ,σ 1), dove ln X- logaritmo naturale X. La densità della distribuzione log-normale è:

Segue dal teorema del limite centrale che il prodotto X = X 1 X 2 … X n variabili casuali positive indipendenti X i, io = 1, 2,…, n, in generale n può essere approssimato da una distribuzione lognormale. In particolare, il modello moltiplicativo della formazione del salario o del reddito porta alla raccomandazione di approssimare le distribuzioni dei salari e dei redditi mediante leggi log-normali. Per la Russia, questa raccomandazione si è rivelata giustificata: le statistiche lo confermano.
Esistono altri modelli probabilistici che portano alla legge log-normale. Un classico esempio di tale modello è dato da A.N. i mulini a palle hanno una distribuzione log-normale.
Passiamo a un'altra famiglia di distribuzioni, ampiamente utilizzata in vari metodi decisionali probabilistico-statistici e in altre ricerche applicate, la famiglia delle distribuzioni esponenziali. Cominciamo con un modello probabilistico che porta a tali distribuzioni. Per fare ciò, considera il "flusso di eventi", ad es. una sequenza di eventi che si verificano uno dopo l'altro in un determinato momento. Esempi sono: flusso di chiamate alla centrale telefonica; il flusso di guasti alle apparecchiature nella catena tecnologica; flusso di guasti del prodotto durante il test del prodotto; il flusso delle richieste dei clienti allo sportello bancario; il flusso di acquirenti che richiedono beni e servizi, ecc. Nella teoria dei flussi di eventi vale un teorema simile al teorema del limite centrale, ma non si tratta della sommatoria di variabili casuali, ma della somma dei flussi di eventi. Consideriamo un flusso totale composto da un gran numero di flussi indipendenti, nessuno dei quali ha un effetto predominante sul flusso totale. Ad esempio, il flusso di chiamate verso una centrale telefonica è costituito da un gran numero di flussi di chiamate indipendenti provenienti dai singoli abbonati. È dimostrato che nel caso in cui le caratteristiche dei flussi non dipendano dal tempo, il flusso totale è completamente descritto da un numero: l'intensità del flusso. Per il flusso totale, considera una variabile casuale X- la durata dell'intervallo di tempo tra eventi successivi. La sua funzione di distribuzione ha la forma
 (10)
(10)
Questa distribuzione è chiamata distribuzione esponenziale perché la formula (10) coinvolge la funzione esponenziale e -λ X. Il valore 1/λ è un parametro di scala. A volte viene introdotto anche un parametro di spostamento Insieme a, esponenziale è la distribuzione di una variabile casuale X + c, dove la distribuzione Xè data dalla formula (10).
Le distribuzioni esponenziali sono un caso speciale del cosiddetto. Distribuzioni Weibull - Gnedenko. Prendono il nome dall'ingegnere W. Weibull, che introdusse queste distribuzioni nella pratica dell'analisi dei risultati dei test di fatica, e dal matematico B.V. Gnedenko (1912-1995), che ricevette distribuzioni come limitanti durante lo studio del massimo del test risultati. Permettere X- una variabile casuale che caratterizza la durata del funzionamento di un prodotto, sistema complesso, elemento (es. risorsa, tempo di funzionamento allo stato limite, ecc.), la durata del funzionamento di un'impresa o la vita di un essere vivente, eccetera. Il tasso di fallimento gioca un ruolo importante
![]() (11)
(11)
dove F(X) e f(X) - funzione di distribuzione e densità di una variabile casuale X.
Descriviamo il comportamento tipico del tasso di guasto. L'intero intervallo di tempo può essere suddiviso in tre periodi. Sul primo di essi, la funzione λ(x) ha valori elevati e una chiara tendenza a diminuire (il più delle volte diminuisce in modo monotono). Ciò può essere spiegato dalla presenza nel lotto in esame di unità di prodotto con difetti evidenti e latenti, che portano a un guasto relativamente rapido di queste unità di prodotto. Il primo periodo è chiamato periodo di "irruzione" (o "irruzione"). Questo di solito è coperto dal periodo di garanzia.
Segue poi il periodo di funzionamento normale, caratterizzato da un tasso di guasto pressoché costante e relativamente basso. La natura dei guasti durante questo periodo è di natura improvvisa (incidenti, errori del personale operativo, ecc.) e non dipende dalla durata del funzionamento di un'unità di prodotto.
Infine, l'ultimo periodo di funzionamento è il periodo di invecchiamento e usura. La natura dei guasti durante questo periodo è in cambiamenti fisici, meccanici e chimici irreversibili nei materiali, che portano a un progressivo deterioramento della qualità di un'unità di produzione e al suo fallimento finale.
Ogni periodo ha il suo tipo di funzione λ(x). Considera la classe delle dipendenze di alimentazione
λ(х) = λ0bxb -1 , (12)
dove λ 0 > 0 e b> 0 - alcuni parametri numerici. I valori b < 1, b= 0 e b> 1 corrispondono al tipo di tasso di guasto durante i periodi di rodaggio, funzionamento normale e invecchiamento, rispettivamente.
Relazione (11) per un dato tasso di fallimento λ(x)- equazione differenziale rispetto alla funzione F(X). Dalla teoria delle equazioni differenziali risulta che
 (13)
(13)
Sostituendo (12) in (13), otteniamo questo
 (14)
(14)
La distribuzione data dalla formula (14) è chiamata distribuzione Weibull - Gnedenko. Perché il
quindi dalla formula (14) segue che la quantità un, dato dalla formula (15), è un parametro di scala. A volte viene introdotto anche un parametro di spostamento, ad es. Weibull - Vengono chiamate le funzioni di distribuzione di Gnedenko F(X - c), dove F(X) è data dalla formula (14) per alcuni λ 0 e b.
La densità della distribuzione Weibull - Gnedenko ha la forma
 (16)
(16)
dove un> 0 - parametro di scala, b> 0 - parametro del modulo, Insieme a- parametro di spostamento. In questo caso, il parametro un dalla formula (16) è relativo al parametro λ 0 dalla formula (14) dal rapporto indicato nella formula (15).
La distribuzione esponenziale è un caso molto particolare della distribuzione Weibull - Gnedenko, corrispondente al valore del parametro shape b = 1.
La distribuzione Weibull - Gnedenko viene utilizzata anche nella costruzione di modelli probabilistici di situazioni in cui il comportamento di un oggetto è determinato dall'"anello più debole". È implicita un'analogia con una catena, la cui sicurezza è determinata da quell'anello che ha la resistenza più bassa. In altre parole, lasciate X 1 , X 2 ,…, X n sono variabili casuali indipendenti distribuite in modo identico,
X(1)=min( X 1 , X 2 ,…, X n), X(n)=massimo( X 1 , X 2 ,…, X n).
In una serie di problemi applicati, un ruolo importante è svolto da X(1) e X(n) , in particolare, quando si studiano i valori massimi possibili ("record") di determinati valori, ad esempio pagamenti o perdite assicurative dovute a rischi commerciali, quando si studiano i limiti di elasticità e resistenza dell'acciaio, una serie di caratteristiche di affidabilità, eccetera. Si mostra che per n grandi le distribuzioni X(1) e X(n) , di regola, sono ben descritti dalle distribuzioni Weibull - Gnedenko. Contributi fondamentali allo studio delle distribuzioni X(1) e X(n) è stato introdotto dal matematico sovietico B.V. Gnedenko. Le opere di V. Weibull, E. Gumbel, V.B. Nevzorova, E.M. Kudlaev e molti altri specialisti.
Passiamo alla famiglia delle distribuzioni gamma. Sono ampiamente utilizzati in economia e gestione, teoria e pratica dell'affidabilità e test, in vari campi della tecnologia, meteorologia, ecc. In particolare, in molte situazioni, la distribuzione gamma è soggetta a grandezze quali la vita utile totale del prodotto, la lunghezza della catena delle particelle di polvere conduttive, il tempo in cui il prodotto raggiunge lo stato limite durante la corrosione, il tempo di funzionamento fino a K il rifiuto, K= 1, 2, …, ecc. L'aspettativa di vita dei pazienti con malattie croniche, il tempo per ottenere un certo effetto nel trattamento in alcuni casi hanno una distribuzione gamma. Questa distribuzione è la più adeguata per descrivere la domanda nei modelli economici e matematici di gestione delle scorte (logistica).
La densità della distribuzione gamma ha la forma
 (17)
(17)
La densità di probabilità nella formula (17) è determinata da tre parametri un, b, c, dove un>0, b>0. in cui unè un parametro del modulo, b- parametro di scala e Insieme a- parametro di spostamento. Fattore 1/Γ(à)è una normalizzazione, viene introdotta per
![]()
Qui Γ(à)- una delle funzioni speciali utilizzate in matematica, la cosiddetta "funzione gamma", con la quale è denominata anche la distribuzione data dalla formula (17),

A un fisso un la formula (17) definisce una famiglia di distribuzioni scale-shift generate da una distribuzione con densità
 (18)
(18)
La distribuzione della forma (18) è chiamata distribuzione gamma standard. Si ottiene dalla formula (17) con b= 1 e Insieme a= 0.
Un caso speciale di distribuzioni gamma a un= 1 sono distribuzioni esponenziali (con λ = 1/b). Con naturale un e Insieme a=0 le distribuzioni gamma sono chiamate distribuzioni di Erlang. Dalle opere dello scienziato danese K.A. Erlang (1878-1929), impiegato della compagnia telefonica di Copenaghen, che studiò nel 1908-1922. il funzionamento delle reti telefoniche, iniziò lo sviluppo della teoria delle code. Questa teoria è impegnata nella modellazione probabilistico-statistica di sistemi in cui il flusso di richieste è servito per prendere decisioni ottimali. Le distribuzioni Erlang sono utilizzate nelle stesse aree di applicazione delle distribuzioni esponenziali. Ciò si basa sul seguente fatto matematico: la somma di k variabili casuali indipendenti distribuite in modo esponenziale con gli stessi parametri λ e Insieme a, ha una distribuzione gamma con parametro shape un =K, parametro di scala b= 1/λ e il parametro di spostamento kc. In Insieme a= 0 otteniamo la distribuzione Erlang.
Se la variabile casuale X ha una distribuzione gamma con parametro di forma un tale che d = 2 un- un numero intero, b= 1 e Insieme a= 0, quindi 2 X ha distribuzione chi quadrato con d gradi di libertà.
Valore casuale X con gvmma-distribution ha le seguenti caratteristiche:
Valore atteso M(X) =ab + c,
dispersione D(X) = σ 2 = ab 2 ,
Il coefficiente di variazione
asimmetria ![]()
Eccesso ![]()
La distribuzione normale è un caso estremo della distribuzione gamma. Più precisamente, sia Z una variabile casuale con una distribuzione gamma standard data dalla formula (18). Quindi
![]()
per qualsiasi numero reale X, dove F(x)- funzione di distribuzione normale standard N(0,1).
Nella ricerca applicata vengono utilizzate anche altre famiglie parametriche di distribuzioni, di cui le più note sono il sistema di curve di Pearson, le serie di Edgeworth e Charlier. Non sono considerati qui.
Discreto distribuzioni utilizzate nei metodi decisionali probabilistico-statistici. Molto spesso vengono utilizzate tre famiglie di distribuzioni discrete: binomiale, ipergeometrica e di Poisson, nonché alcune altre famiglie: geometrica, binomiale negativa, multinomiale, ipergeometrica negativa, ecc.
Come già accennato, la distribuzione binomiale avviene in prove indipendenti, in ognuna delle quali con probabilità R appare l'evento MA. Se il numero totale di prove n dato, quindi il numero di prove Y, in cui è apparso l'evento MA, ha una distribuzione binomiale. Per una distribuzione binomiale, la probabilità di essere accettata come variabile casuale Y i valori yè determinato dalla formula
![]()
Numero di combinazioni da n elementi di y noto dalla combinatoria. Per tutti y, ad eccezione di 0, 1, 2, …, n, noi abbiamo P(Y= y)= 0. Distribuzione binomiale con una dimensione campionaria fissa nè impostato dal parametro p, cioè. le distribuzioni binomiali formano una famiglia a un parametro. Sono utilizzati nell'analisi di dati di ricerca campionari, in particolare nello studio delle preferenze dei consumatori, nel controllo selettivo della qualità del prodotto secondo piani di controllo a stadio singolo, quando si testano popolazioni di individui in demografia, sociologia, medicina, biologia, ecc.
Se una Y 1 e Y 2 - variabili casuali binomiali indipendenti con lo stesso parametro p 0 determinato da campioni con volumi n 1 e n 2 rispettivamente, quindi Y 1 + Y 2 - variabile casuale binomiale con distribuzione (19) con R = p 0 e n = n 1 + n 2 . Questa osservazione amplia l'applicabilità della distribuzione binomiale, consentendo di combinare i risultati di più gruppi di test, quando vi è motivo di ritenere che lo stesso parametro corrisponda a tutti questi gruppi.
Le caratteristiche della distribuzione binomiale sono state calcolate in precedenza:
M(Y) = np, D(Y) = np( 1- p).
Nella sezione "Eventi e probabilità" per una variabile casuale binomiale si dimostra la legge dei grandi numeri:
![]()
per chiunque . Con l'aiuto del teorema del limite centrale, la legge dei grandi numeri può essere affinata indicando come Y/ n si differenzia da R.
Teorema di De Moivre-Laplace. Per qualsiasi numero a e b, un< b, noi abbiamo

dove F(X) è una funzione di distribuzione normale standard con media 0 e varianza 1.
Per dimostrarlo basta usare la rappresentazione Y come somma di variabili casuali indipendenti corrispondenti ai risultati dei singoli studi, formule per M(Y) e D(Y) e il teorema del limite centrale.
Questo teorema è per il caso R= ½ fu dimostrato dal matematico inglese A. Moivre (1667-1754) nel 1730. Nella formulazione di cui sopra, fu dimostrato nel 1810 dal matematico francese Pierre Simon Laplace (1749-1827).
La distribuzione ipergeometrica avviene durante il controllo selettivo di un insieme finito di oggetti di volume N secondo una caratteristica alternativa. Ogni oggetto controllato è classificato come avente l'attributo MA, o come non in possesso di questa caratteristica. La distribuzione ipergeometrica ha una variabile casuale Y, uguale al numero di oggetti che hanno l'attributo MA in un campione casuale di volume n, dove n< N. Ad esempio, numero Y unità difettose di prodotti in un campione casuale di volume n dal volume del lotto N ha una distribuzione ipergeometrica se n< N. Un altro esempio è la lotteria. Lascia il segno MA un biglietto è un segno di “vincere”. Lascia che tutti i biglietti N, e qualche persona ha acquisito n di loro. Quindi il numero di biglietti vincenti per questa persona ha una distribuzione ipergeometrica.
Per una distribuzione ipergeometrica, la probabilità che una variabile casuale Y assuma il valore y ha la forma
 (20)
(20)
dove Dè il numero di oggetti che hanno l'attributo MA, nell'insieme di volume considerato N. in cui y prende valori da max(0, n - (N - D)) al minimo( n, D), con altri y la probabilità nella formula (20) è uguale a 0. Pertanto, la distribuzione ipergeometrica è determinata da tre parametri: il volume della popolazione generale N, numero di oggetti D in esso, possedendo la caratteristica considerata MA, e la dimensione del campione n.
Campionamento casuale semplice n dal volume totale Nè chiamato un campione ottenuto come risultato di una selezione casuale, in cui uno qualsiasi degli insiemi da n gli oggetti hanno la stessa probabilità di essere selezionati. I metodi per la selezione casuale di campioni di intervistati (intervistati) o unità di prodotti in pezzi sono considerati nei documenti istruttivi-metodici e normativo-tecnici. Uno dei metodi di selezione è il seguente: gli oggetti vengono selezionati uno dall'altro e ad ogni passaggio ciascuno degli oggetti rimanenti nel set ha la stessa possibilità di essere selezionato. In letteratura, per la tipologia di campioni in esame, vengono utilizzati anche i termini “campione casuale”, “campione casuale senza sostituzione”.
Poiché i volumi della popolazione generale (lotti) N e campioni n sono comunemente noti, allora il parametro di distribuzione ipergeometrica da stimare è D. Nei metodi statistici di gestione della qualità del prodotto D- di solito il numero di unità difettose nel lotto. Interessante è anche la caratteristica della distribuzione D/ N- livello di difetto.
Per distribuzione ipergeometrica
L'ultimo fattore nell'espressione di varianza è vicino a 1 se N>10 n. Se, contemporaneamente, facciamo la sostituzione p = D/ N, quindi le espressioni per l'aspettativa matematica e la varianza della distribuzione ipergeometrica si trasformeranno in espressioni per l'aspettativa matematica e la varianza della distribuzione binomiale. Questa non è una coincidenza. Si può dimostrare che

a N>10 n, dove p = D/ N. Il rapporto limite è valido
e questa relazione limitante può essere usata per N>10 n.
La terza distribuzione discreta ampiamente utilizzata è la distribuzione di Poisson. Una variabile casuale Y ha una distribuzione di Poisson se
![]() ,
,
dove λ è il parametro della distribuzione di Poisson, e P(Y= y)= 0 per tutti gli altri y(per y=0, si denota 0!=1). Per la distribuzione di Poisson
M(Y) = λ, D(Y) = λ.
Questa distribuzione prende il nome dal matematico francese CD Poisson (1781-1840), che per primo la derivò nel 1837. La distribuzione di Poisson è un caso estremo della distribuzione binomiale, dove la probabilità R l'attuazione dell'evento è piccola, ma il numero di prove n grande, e np= λ. Più precisamente, la relazione limite
Pertanto, la distribuzione di Poisson (nella vecchia terminologia "legge di distribuzione") è spesso chiamata anche "legge degli eventi rari".
La distribuzione di Poisson nasce nella teoria dei flussi di eventi (vedi sopra). Si dimostra che per il flusso più semplice con intensità costante Λ, il numero di eventi (chiamate) avvenuti nel tempo t, ha una distribuzione di Poisson con parametro λ = Λ t. Pertanto, la probabilità che nel tempo t non si verificherà alcun evento e - Λ t, cioè. la funzione di distribuzione della lunghezza dell'intervallo tra gli eventi è esponenziale.
La distribuzione di Poisson viene utilizzata nell'analisi dei risultati delle indagini di marketing selettive presso i consumatori, nel calcolo delle caratteristiche operative dei piani di controllo statistico di accettazione in caso di piccoli valori del livello di accettazione della difettosità, per descrivere il numero di guasti di un processo tecnologico statisticamente controllato per unità di tempo, il numero di "fabbisogni di servizio" in arrivo per unità di tempo nel sistema di code, modelli statistici di incidenti e malattie rare, ecc.
In letteratura vengono considerate la descrizione di altre famiglie parametriche di distribuzioni discrete e la possibilità del loro uso pratico.
In alcuni casi, ad esempio, quando si studiano i prezzi, i volumi di produzione o il tempo totale tra i guasti nei problemi di affidabilità, le funzioni di distribuzione sono costanti su determinati intervalli in cui i valori delle variabili casuali oggetto di studio non possono cadere.
| Precedente |
La funzione di distribuzione di una variabile casuale X è la funzione F(x), che esprime per ogni x la probabilità che la variabile casuale X assuma il valore, x più piccolo
Esempio 2.5. Data una serie di distribuzioni di una variabile casuale
Trova e rappresenta graficamente la sua funzione di distribuzione. Soluzione. Secondo la definizione
F(jc) = 0 per X X
F(x) = 0,4 + 0,1 = 0,5 a 4 F(x) = 0,5 + 0,5 = 1 a X > 5.
Quindi (vedi Fig. 2.1):


Proprietà della funzione di distribuzione:
1. La funzione di distribuzione di una variabile casuale è una funzione non negativa racchiusa tra zero e uno: ![]()
2. La funzione di distribuzione di una variabile casuale è una funzione non decrescente sull'intero asse dei numeri, ad es. a X 2 >x
![]()
3. A meno infinito, la funzione di distribuzione è uguale a zero, a più infinito, è uguale a uno, cioè
4. Probabilità di colpire una variabile casuale X nell'intervalloè uguale all'integrale definito della sua densità di probabilità che va da un prima b(vedi Fig. 2.2), cioè

Riso. 2.2
3. La funzione di distribuzione di una variabile casuale continua (vedi Fig. 2.3) può essere espressa in termini di densità di probabilità usando la formula:
F(x)= Jp(*)*. (2.10)
4. L'integrale improprio nei limiti infiniti della densità di probabilità di una variabile casuale continua è uguale a uno:
Proprietà geometriche / e 4 densità di probabilità significano che la sua trama è curva di distribuzione - non si trova al di sotto dell'asse x, e l'area totale della figura, curva di distribuzione limitata e asse x, è uguale a uno.
Per una variabile casuale continua X valore atteso M(X) e varianza D(X) sono determinati dalle formule:
(se l'integrale converge assolutamente); o 
(se gli integrali ridotti convergono).
Insieme alle caratteristiche numeriche sopra riportate, il concetto di quantili e punti percentuali viene utilizzato per descrivere una variabile casuale.
q livello quantile(o q-quantile) è un tale valorexqvariabile casuale, in cui la sua funzione di distribuzione assume il valore, uguale a q, cioè.
- 100Il punto q%-ou è il quantile X~ q .
- ? Esempio 2.8.
Secondo l'esempio 2.6 trova il quantile xqj e 30% punto variabile casuale X.
Soluzione. Per definizione (2.16) F(xo t3)= 0.3, cioè
~Y~ = 0.3, da cui il quantile x 0 3 = 0,6. 30% punto variabile casuale X, o quantile Х)_о,з = xoj» si trova in modo simile dall'equazione ^ = 0,7. da cui *,= 1.4. ?
Tra le caratteristiche numeriche di una variabile casuale, ci sono iniziale v* e centrale R* Momenti di k-esimo ordine, determinato per variabili casuali discrete e continue dalle formule:

Definizione della funzione di distribuzione
Sia $X$ una variabile casuale e $x$ la probabilità di distribuzione di questa variabile casuale.
Definizione 1
Una funzione di distribuzione è una funzione $F(x)$ che soddisfa la condizione $F\sinistra(x\destra)=P(X
Inoltre, a volte viene chiamata la funzione di distribuzione funzione di distribuzione cumulativa o legge della distribuzione integrale.
In generale, il grafico della funzione di distribuzione è un grafico di una funzione non decrescente con un range di valori appartenente al segmento $\left$ (inoltre, 0 e 1 sono necessariamente inclusi nel range di valori). In questo caso, la funzione può avere o meno salti della funzione (Fig. 1)
Figura 1. Un esempio di diagramma di funzione di distribuzione
Funzione di distribuzione di una variabile casuale discreta
Sia discreta la variabile casuale $X$. E gli sia dato un numero della sua distribuzione. Per tale valore, la funzione di distribuzione di probabilità può essere scritta nella forma seguente:

Funzione di distribuzione di una variabile casuale continua
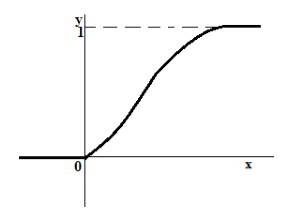
Lascia che la variabile casuale $X$ sia ora continua.
Il grafico della funzione di distribuzione di tale variabile casuale è sempre una funzione continua non decrescente (Fig. 3).
Consideriamo ora il caso in cui la variabile casuale $X$ è mista.
Il grafico della funzione di distribuzione di tale variabile casuale è sempre una funzione non decrescente, che ha un valore minimo di 0, un valore massimo di 1, ma che non è una funzione continua sull'intero dominio di definizione (cioè, ha salti in singoli punti) (Fig. 4).
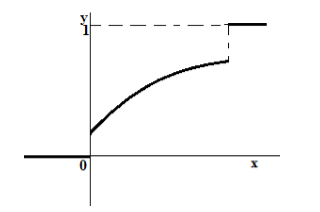
Figura 4. Funzione di distribuzione di una variabile casuale mista
Esempi di problemi per trovare la funzione di distribuzione
Esempio 1
Vengono fornite alcune distribuzioni del verificarsi dell'evento $A$ in tre esperimenti
Figura 5
Trova la funzione di distribuzione di probabilità e costruisci il suo grafico.
Soluzione.
Poiché la variabile casuale è discreta, possiamo usare la formula $\ F\left(x\right)=\sum\limits_(x_i
Per $x>3$, $F\sinistra(x\destra)=0.2+0.1+0.3+0.4=1$;
Da ciò otteniamo la seguente funzione di distribuzione di probabilità:
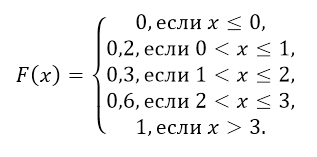
Figura 6
Tracciamolo:

Figura 7
Esempio 2
Viene eseguito un esperimento, in cui l'evento $A$ può verificarsi o meno. La probabilità che questo evento si verifichi è di $ 0,6 $. Trova e costruisci la funzione di distribuzione di una variabile casuale.
Soluzione.
Poiché la probabilità che si verifichi l'evento $A$ è di $0,6$, la probabilità che questo evento non si verifichi è di $1-0,6=0,4$.
Per prima cosa, costruiamo una serie di distribuzioni di questa variabile casuale:
Figura 8
Poiché la variabile casuale è discreta, troviamo la funzione di distribuzione per analogia con il problema 1:
Per $x\le 0$, $F\sinistra(x\destra)=0$;
Per $x>1$, $F\sinistra(x\destra)=0,4+0,6=1$;
Quindi, otteniamo la seguente funzione di distribuzione:

Figura 9
Tracciamolo:

Figura 10.
Funzione di distribuzione di probabilità e sue proprietà.
La funzione di distribuzione di probabilità F(x) di una variabile aleatoria X in un punto x è la probabilità che, a seguito dell'esperimento, la variabile aleatoria assuma un valore minore di x, cioè F(x)=P(X< х}.
Considera le proprietà della funzione F(x).
1. F(-∞)=lim (x→-∞) F(x)=0. Infatti, per definizione, F(-∞)=P(X< -∞}. Событие (X < -∞) является невозможным событием: F(-∞)=P{X < - ∞}=p{V}=0.
2. F(∞)=lim (x→∞) F(x)=1, poiché, per definizione, F(∞)=P(X< ∞}. Событие Х < ∞ является достоверным событием. Следовательно, F(∞)=P{X < ∞}=p{U}=1.
3. La probabilità che una variabile casuale assuma un valore dall'intervallo [Α Β] è uguale all'incremento della funzione di distribuzione di probabilità su questo intervallo. P(Α ≤X<Β}=F(Β)-F(Α).
4. F(x 2)≥ F(x 1), se x 2, > x 1, cioè la funzione di distribuzione di probabilità è una funzione non decrescente.
5. La funzione di distribuzione di probabilità è continua a sinistra. FΨ(x o -0)=limFΨ(x)=FΨ(x o) per x→ x o
Le differenze tra le funzioni di distribuzione di probabilità di variabili casuali discrete e continue sono ben illustrate dai grafici. Supponiamo, ad esempio, che una variabile casuale discreta abbia n valori possibili, le cui probabilità sono P(X=x k )=p k , k=1,2,..n. Se x ≤ x 1, allora F(X)=0, poiché non ci sono valori possibili della variabile casuale a sinistra di x. Se x 1< x ≤ x 2 , то левее х находится всего одно возможное значение, а именно, значение х 1 .

Quindi, F(x)=P(X=x 1 )=p 1. Quando x 2< x ≤ x 3 слева от х находится уже два возможных значения, поэтому F(x)=P{X=x 1 }+P{X=x 2 }=p 1 +p 2 . Рассуждая аналогично,приходим к выводу, что если х k < x≤ x k+1 , то F(x)=1, так как функция будет равна сумме вероятностей всех возможных значений, которая по условию нормировки равна еденице. Таким образом, график функции распределения дискретной случайной величины является ступенчатым. Возможные значения непрерывной величины располагаются плотно на интервале задания этой величины, что обеспечивает плавное возрастания функции распределения F(x), т.е. ее непрерывность.
Si consideri la probabilità che una variabile casuale rientri nell'intervallo , Δx>0: P(x≤X< x+Δx}=F(x+ Δx)-F(x). Перейдем к пределу при Δx→0:
lim (Δx→0) P(x≤ X< x+Δx}=lim (Δx→0) F(x+Δx)-F(x). Предел равен вероятности того, что случайная величина примет значение, равное х. Если функция F(x) непрерывна в точке х, то lim (Δx→0) F(x+Δx)=F(x), т.е. P{X=x}=0.
Se F(x) ha una discontinuità nel punto x, allora la probabilità P(X=x) sarà uguale al salto della funzione in quel punto. Pertanto, la probabilità di occorrenza di qualsiasi valore possibile per una quantità continua è zero. L'espressione P(X=x)=0 va intesa come il limite della probabilità che una variabile aleatoria cada in un intorno infinitamente piccolo del punto x per P(Α< X≤ Β},P{Α ≤ X< Β},P{Α< X< Β},P{Α ≤ X≤ Β} равны, если Х - непрерывная случайная величина.
Per le variabili discrete, queste probabilità non sono le stesse nel caso in cui i limiti dell'intervallo Α e (o) Β coincidano con i possibili valori delle variabili casuali. Per una variabile casuale discreta, è necessario tenere rigorosamente conto del tipo di disuguaglianza nella formula P(Α ≤X<Β}=F(Β)-F(Α).

